
m6米乐在线入口m6米乐在线入口【新智元导读】刚刚,继4月初获得5.28亿融资后,短短2个月,国内顶尖具身智能玩家又斩获近6亿元融资!不久前,其首款商用级人形机器人Moz1震撼发布,可单手精准抽纸,具备超强感知与执行力。凭借三维核心竞争力,他们正向万亿级赛道加速冲刺。

Figure AI自研的端到端VLA模型——Helix,让机器人从语言理解到动作执行一气呵成;

还有UC伯克利系出身的Physical Intelligence,多次迭代π系列模型,通过多平台训练,攻克了洗衣、收纳等复杂任务。

可见,在这片巨大红海中,从不缺少重量级玩家。在技术迭代与资本助推下,全球的目光都聚焦于这场通往「通用机器人」的终极竞赛。
本轮融资由京东领投,中国互联网投资基金(简称「中网投」)、浙江省科创母基金、华泰紫金、复星锐正等知名机构跟投。
堪称传奇的是,从2024年2月成立至今,这家公司便以惊人速度完成了多轮融资,成为资本市场的宠儿。
更值得关注的是,上一轮领投的P7在本轮持续超额加码;除此之外,顺为资本、华控基金、华发集团、千乘资本、靖亚资本、弘晖基金等老股东的继续下注,则是对千寻发展潜力的持续背书。
作为中国电商与物流巨擘,京东的投资逻辑清晰且务实:聚焦核心业务效率、优化用户体验,并推动产业升级的技术创新。
京东集团出手,不仅彰显了千寻在物流等高价值场景的潜力,也折射出其在具身智能赛道中的独特价值。
千寻创始人兼CEO韩峰涛表示,「重量级产投方的齐聚,不仅是对千寻智能的认可,更折射出产业界对具身智能赛道未来价值的高度共识」。
因为基于全球功率密度最高的一体化力控关节打造,它在速度、精度、安全性和仿生力控方面,都达到了行业的头部水平。

据悉,Moz1一体化关节的功率密度直接比特斯拉Optimus高出了15%,充分展示了千寻智能在机器人硬件上的强大实力


同时,因为还内置了自研的度数采设备(比如VR/动捕/同构形等),Moz 1能够实现模型的小时级迭代,以极其硬核的硬件,充分支撑技术落地。
看着它在公司内部来回穿梭、充分融入大家工作流的样子,我们就知道——如今,是时候重新定义「劳动力」了!


在商用场景,它可以丝滑完成整理、接待、导览等任务,那么家庭场景的陪伴、互动和服务,当然也不在话下了。

千寻首款商用级Moz1人形机器人之所以具备强大理解泛化能力,离不开具身智能「大脑」VLA(视觉-语言-动作)模型的加持。
为此,千寻自研了一款端到端具身模型——Spirit v1,通过数据融合与训练策略,实现了视觉感知、语言理解、动作执行的无缝衔接。
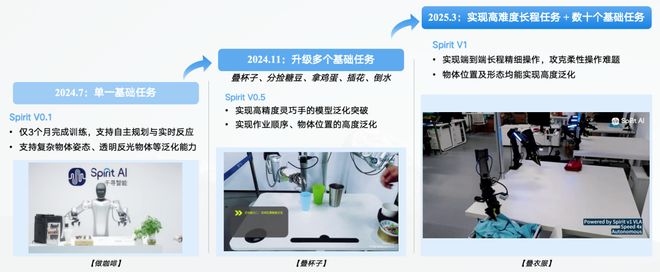
Spirit系模型在短短半年的时间迭代了三版,实现了从单一基础任务到高难度长程+数十个任务完成的阶跃式进步
举个栗子,叠衣服这一看似简单的任务,实则对机器人提出了极高挑战:每件衣服的褶皱、形状各异,要比抓糖豆、倒水等任务高出百倍。
Spirit v1通过动态场景感知和精确动作控制,完成了从抓取、铺平、折叠到堆叠的全流程,成功率达70%-80%。
Spirit v1的成功,源于其独特的三层训练架构,通过融合视频预训练、遥操模仿学习和RL,构建了高效、泛化的技术壁垒。
这款VLA模型共有70亿参数,基于13000小时数据训练。其中,70%来自海量的互联网视频。
通过端到端学习米乐m6官方网站,Spirit v1直接从视频中提取视觉和动作信息,掌握物体的形态变化、动作逻辑,以及场景动态性。
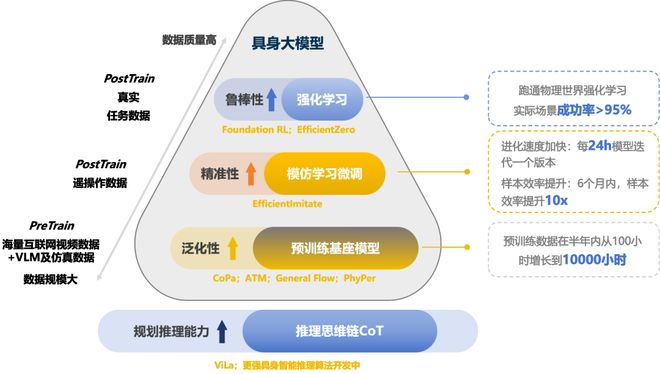
在预训练基础上,20%的遥操数据通过千寻自研的EfficientImitate算法进行精调。
在端到端框架下,遥操作模仿学习进一步优化了Spirit v1性能,实现了从示范到自助操作的平滑过渡。

剩余10%的强化学习数据,则采用全球样本效率最高的EfficientZero强化学习算法,让机器人通过自主探索优化行为策略。


以上三层架构,不仅解决了训练「数据荒」的瓶颈,还让Spirit v1在动态环境中展现出强大的自主性和适应性。
更令人瞩目的是,今年5月米乐m6官方网站,千寻首席科学家高阳带领团队提出了OneTwoVLA模型,实现了全新的突破。
这一创新架构将传统机器人系统中,分离的「推理大脑」和「动作四肢」熔炼为单一Transformer模型,真正实现了「边想边做」。

在长程任务实验中,OneTwoVLA加持的机器人能顺利流畅完成涮火锅、炒菜、调鸡尾酒等复杂任务,成功率比纯动作VLA提升30%。
如下示例中,当你要求「帮我涮牛肉」,OneTwoVLA会在每一步预测开始推理,还是开始执行。
OneTwoVLA的通用视觉定位,还能准确识别未见过的雪碧罐,或是星巴克杯子,展现了超强的开放世界理解能力。

OneTwoVLA的代码与数据已全部开源,标志着千寻在通用机器人技术路线上的新里程碑,也为行业提供了更简洁、可扩展的具身智能路径。
他们基于成熟的商业化经验,精准切入高价值场景,大规模部署高效收集的海量数据,持续反哺模型优化。
在办公场景中,千寻机器人展现出了强大的灵活性。我们看到了,Moz1能自主完成会议室清洁任务,收纳笔、擦拭白板等等。

据判断,在物流场景中,智能仓储体系对高效、灵活机器人的需求将极其旺盛,正好千寻机器人也能适配货物分拣、动态搬运等复杂任务。
放眼未来,千寻还计划从办公场景逐步向制造、服务业、医疗、康养等高附加值场景渗透,目标直指万亿级市场。
尤其在海外市场,欧美高人工的成本地区,付费意愿强。而创始团队的国际化经验,恰恰为其提供了坚实支撑。
深挖之后可以发现,在如今竞争激烈的具身赛道,最终突出重围的之所以是千寻智能,还是因为它走了一条「少有人走的路」。


